
Experience
~4 years across Data Engineering and Data Analysis
Data Engineering · Analytics · Azure
I’m Ninad, a UK-based Data Engineer & Data Analyst focused on building Azure & Databricks-centric pipelines, Medallion lakehouses, and analytics that business teams actually use.

Get to know me
I work at the intersection of data engineering and analytics, designing pipelines that keep stakeholders out of CSV hell. My day-to-day includes building Azure Databricks Medallion architectures, orchestrating ingestion with ADF, and modelling trusted Power BI datasets that Finance, Operations, and Marketing use every day.
I enjoy turning ambiguous business questions into concrete models, metrics, and dashboards – from near real-time drink league boards at The DRG to SCD2 dimensions in Databricks and governed Snowflake warehouses. My portfolio reflects end-to-end thinking: ingestion, modelling, optimisation, BI, and documentation.
~4 years across Data Engineering and Data Analysis

MSc in Advance Computer Science with Data Science (UK) with a focus on cloud, Python, and modern BI; strong foundation in statistics and SQL.
Building Azure-centric pipelines at The DRG, expanding portfolio projects in Databricks, dbt, Snowflake and streaming.
Recent journey
The DRG · UK
May 2024 – Present
NSEIT Limited
Apr 2021 – Mar 2022
Swami Vivekanand Education and Research Centre
Mar 2020 – Mar 2021
What I work with
Azure (ADLS Gen2, Databricks, ADF, Logic Apps, SQL DB, SQL Warehouse), Snowflake for analytics warehousing and dbt-driven transformations.
ETL/ELT, CDC, Medallion architecture, Delta Live Tables, SCD2 dims, Type-1 facts, data quality rules and observability.
Azure Data Factory (Copy, Mapping Data Flows, SHIR), Logic Apps, GitHub Actions and Databricks Asset Bundles for CI/CD.
Python (Pandas, requests, automation), SQL (PostgreSQL, MySQL), DAX, REST / HTTP APIs, JSON / XML handling.
Power BI (DAX, Row-Level Security, modelling), advanced Excel, and clear stakeholder-facing data stories.
Docker, Git/GitHub, documentation & runbooks, plus a strong focus on reproducible, production-friendly data workflows.
Selected work
A mix of Azure, Databricks, ADF, dbt, Snowflake and streaming projects that demonstrate end-to-end thinking.
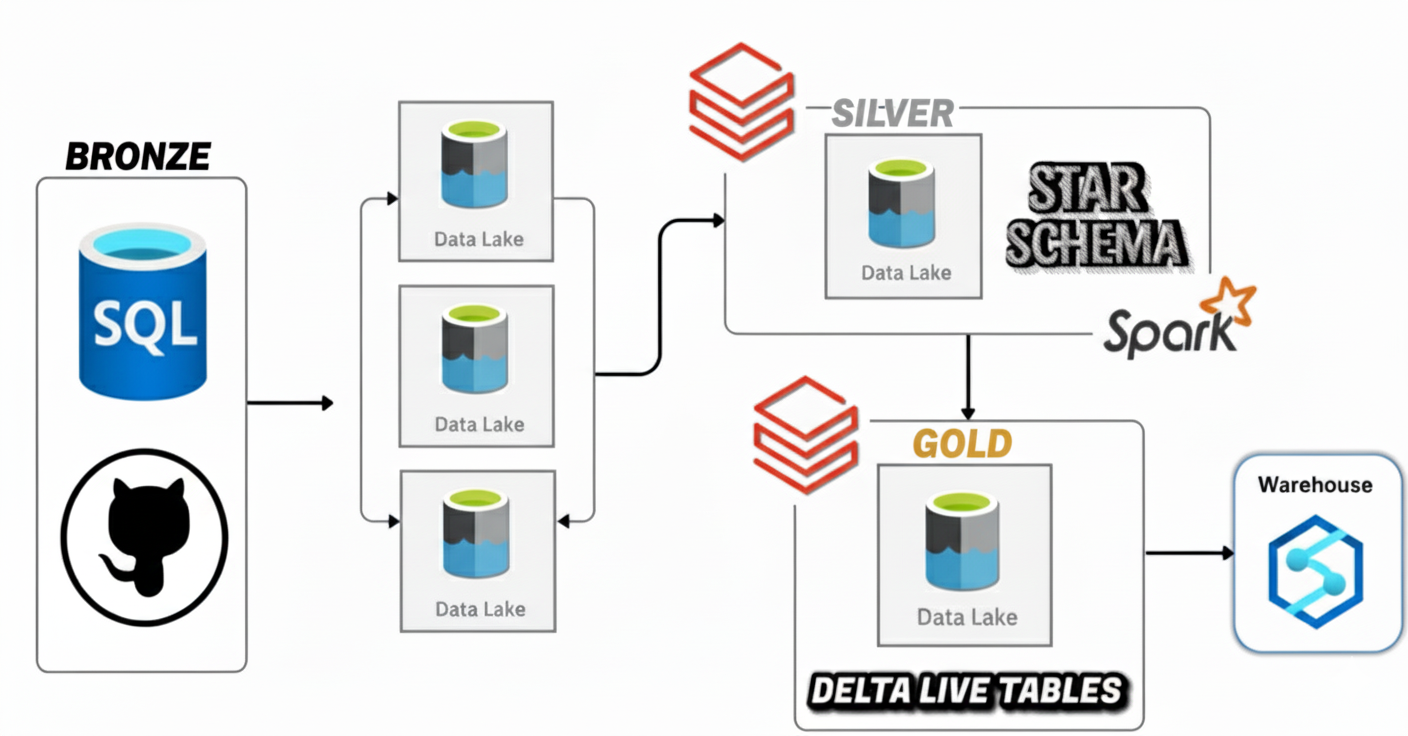 Azure · Databricks · DLT
Azure · Databricks · DLT
This project is a full Azure Data Engineering build that ingests from a cloud-hosted Azure SQL Database into ADLS Gen2 using Azure Data Factory (ADF) with incremental loading and backfilling (not a full refresh). Data is refined in Azure Databricks with Spark Structured Streaming + Autoloader, governed by Unity Catalog, and modeled into a star schema with Slowly Changing Dimensions (SCD Type 2). The Gold layer is curated via Delta Live Tables (DLT), and deployments follow CI/CD best practices using Databricks Asset Bundles and GitHub. Logic Apps provide email alerts on ADF failures. The project also covers the full resource setup (RG, Storage with bronze/silver/gold, ADF, SQL DB, Databricks workspace).
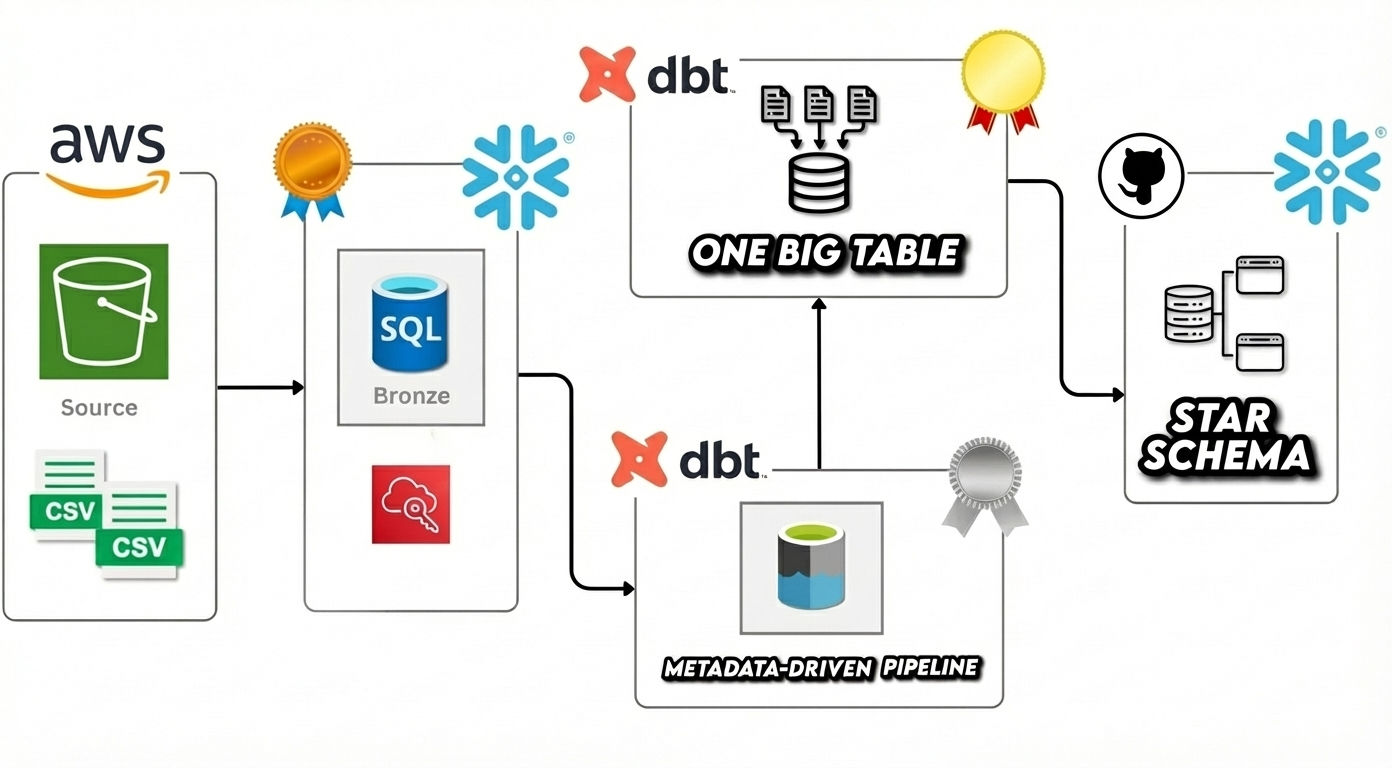 AWS S3· Snowflake · dbt
AWS S3· Snowflake · dbt
This project showcases a full ELT pipeline built with AWS S3 → Snowflake → dbt, designed around a Bronze/Silver/Gold modeling approach. I ingested Airbnb-style CSV datasets into Snowflake using stages and COPY INTO, then used dbt to build incremental raw models (Bronze), cleaned and enriched models (Silver), and analytics-ready models (Gold). The Gold layer includes a metadata-driven OBT for maintainable joins and a Star Schema powered by SCD2 snapshots to preserve dimensional history for accurate time-based reporting
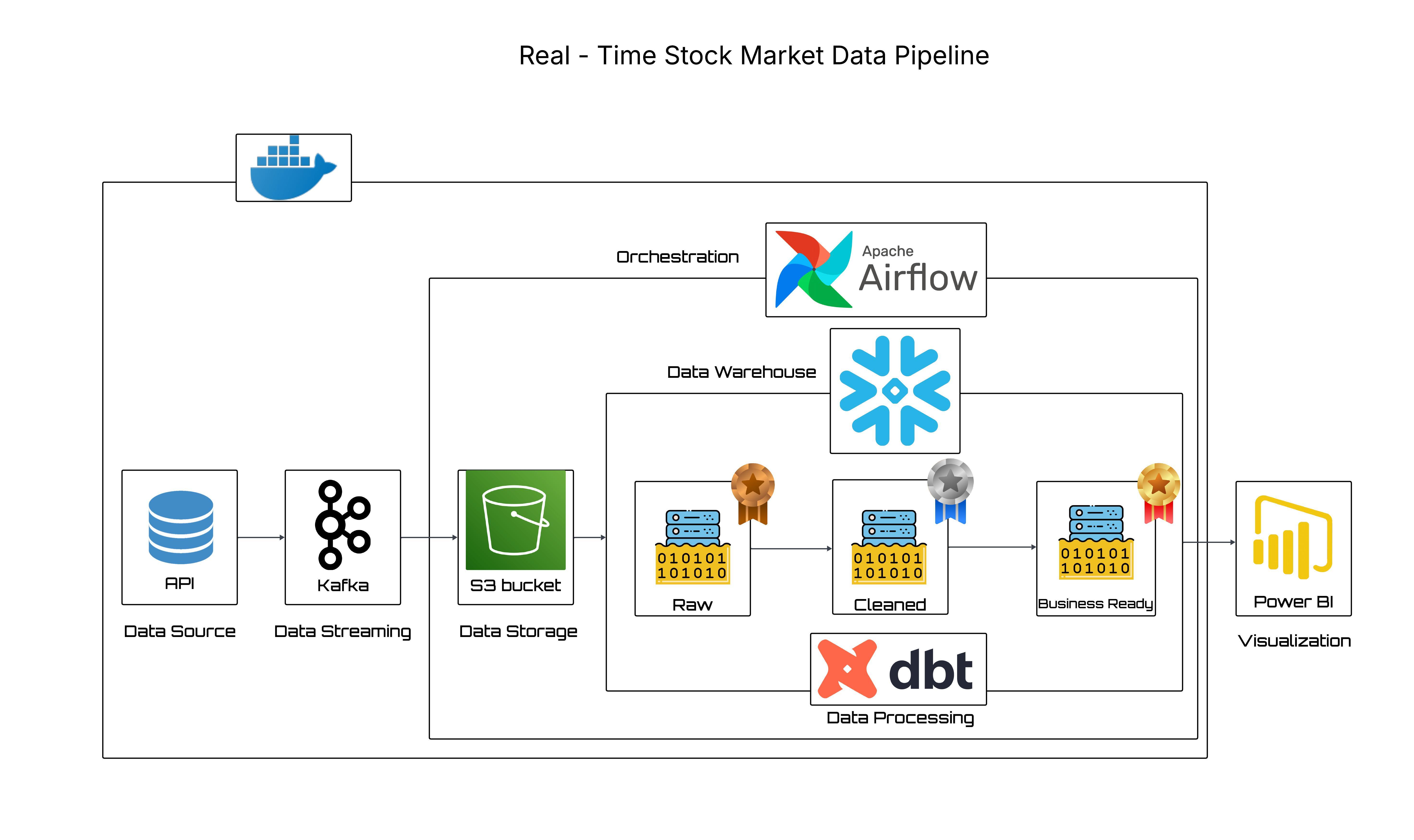 Kafka · Snowflake · dbt
Kafka · Snowflake · dbt
I built a real-time Stock Market Data Pipeline that streams live quotes end-to-end for fast, reliable analytics. Kafka ingests events to an S3 raw landing zone, and Airflow micro-batches them into Snowflake via stage-based PUT/COPY with idempotent loads. In Snowflake, dbt applies the Medallion pattern (Bronze/Silver/Gold), converting JSON VARIANT into clean, tested, lineage-tracked models. The entire stack runs in Docker Compose, enabling one-command spin-up and easy portability across environments. ~1-minute KPIs and candlesticks for BI with strong governance, observability, and clear separation of concerns.
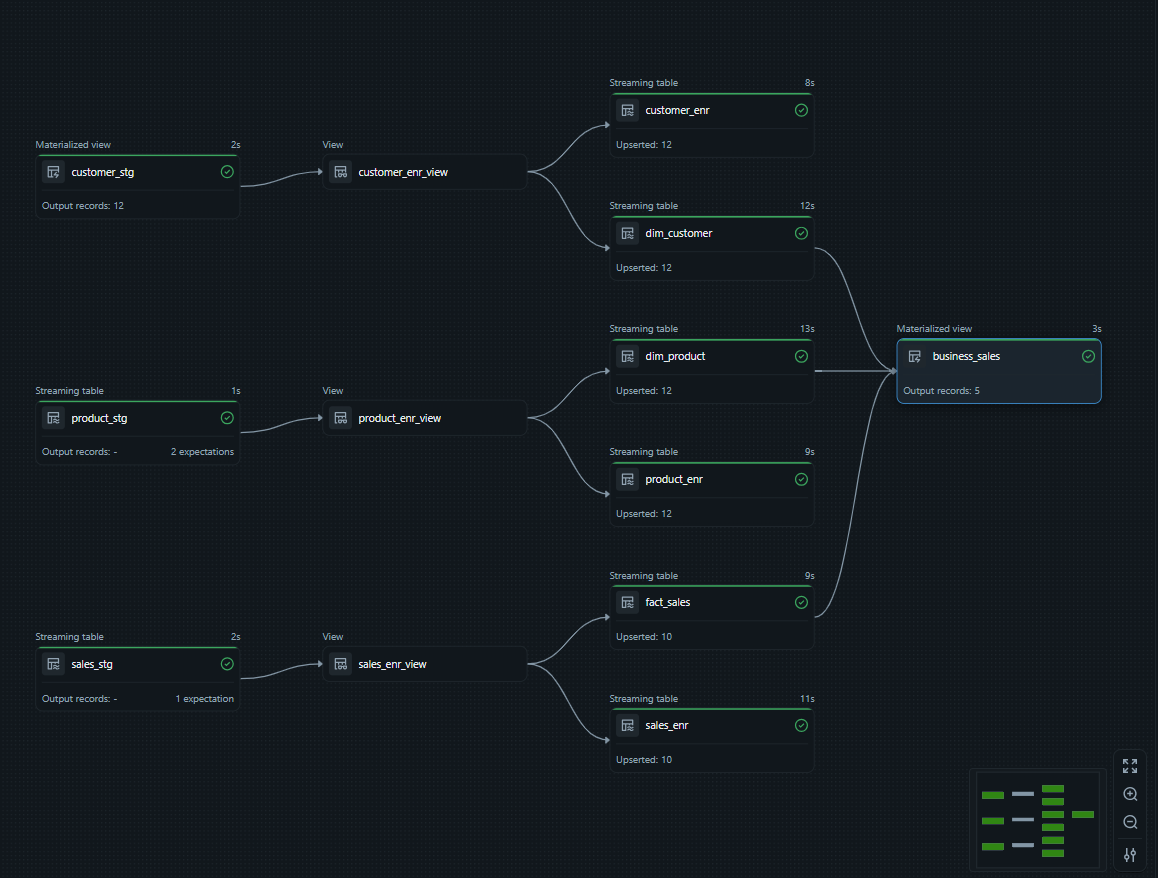 Databricks · DLT
Databricks · DLT
This project delivers an end-to-end Databricks Lakehouse built entirely with Lakeflow Declarative Pipelines (DLT). It implements the Medallion pattern: Bronze landing with Expectations, Silver enrichment via Auto-CDC (Type-1 upserts) exposed through stable views, and Gold with SCD2 dimensions, a Type-1 fact table, and a full-history materialized business view. The project supports streaming and batch in one pipeline, comes with reusable utilities, and provides SQL scripts to seed/increment data plus screenshots of each stage.
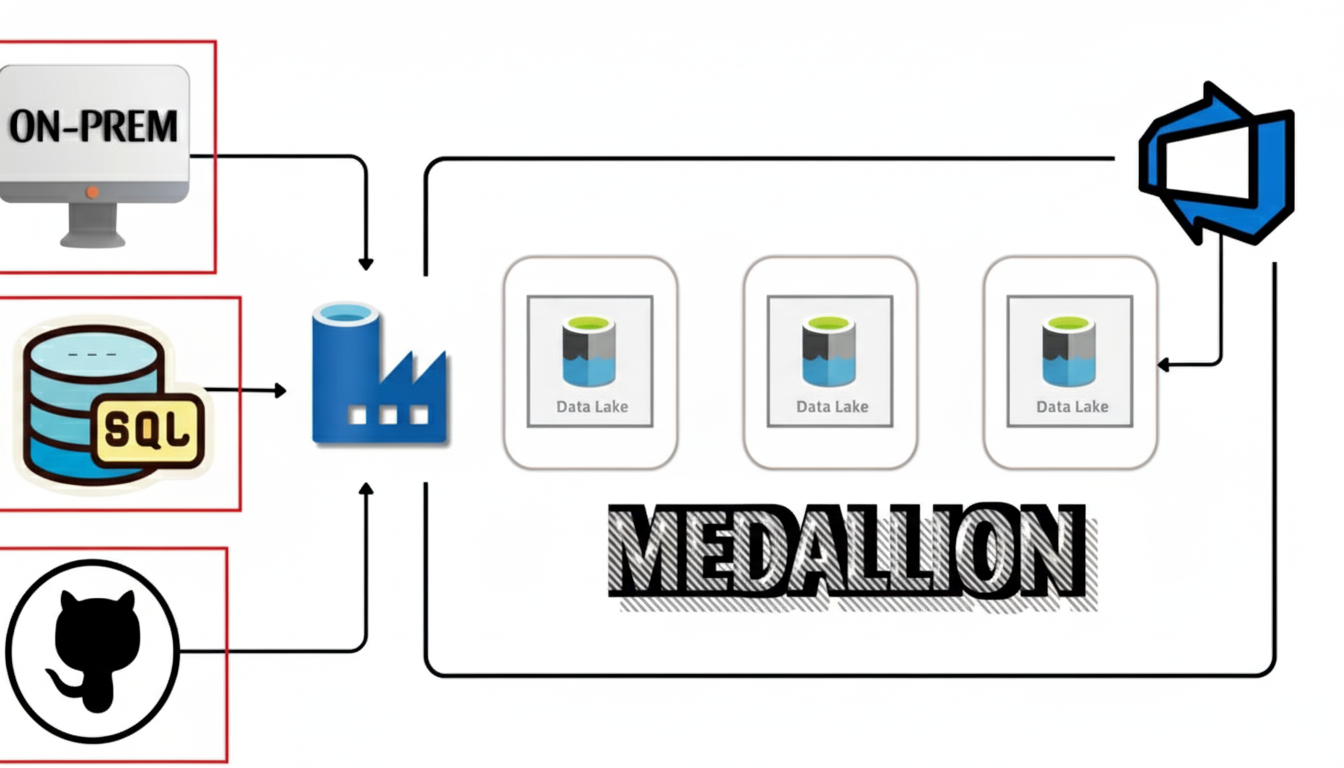 Azure · ADF · Medallion
Azure · ADF · Medallion
This project is a production-style Azure Data Factory (ADF) build that ingests data from on-prem file shares, REST APIs, and Azure SQL Database into ADLS Gen2. It models the data using the Medallion architecture: Bronze – fast, schema-light landing (CSV/JSON/Parquet/Delta) for raw capture; Silver – standardized Delta with data cleaning, type casting, derivations, and upsert logic keyed by business IDs; Gold – curated business views (joins, aggregations, dense ranking, Top-N) refreshed with overwrite. Orchestration is handled by a Parent Pipeline that chains the three ingestion paths and kicks off transformations. Hybrid connectivity to the on-prem share is enabled via Self-Hosted Integration Runtime (SHIR). A publish folder is included for ARM-based CI/CD.
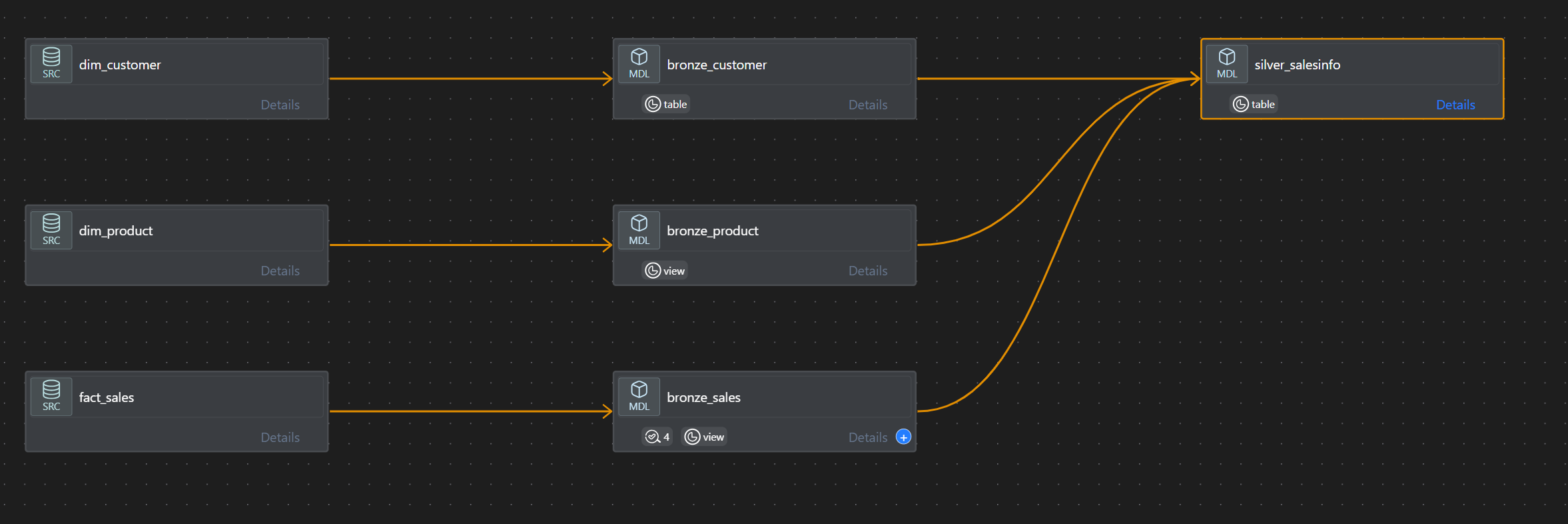 dbt · Databricks
dbt · Databricks
A production-style dbt Core project on Databricks (Unity Catalog) implementing the Medallion architecture (Bronze → Silver → Gold). Raw sources are declared in YAML and landed to Bronze, standardized and joined in Silver, and delivered as analytics marts in Gold with SCD Type-2 history via dbt snapshots. Quality is enforced through generic, singular, and custom generic tests, plus seeds for lookups and Jinja macros for reusable logic. The repo uses environment-driven profiles.yml, clear lineage, incremental dbt models, and a CI-friendly dbt build flow making it reliable, auditable, and deployment-ready.
More projects coming soon…
Get in touch
Whether it’s a data engineering role, a project collaboration, or just a chat about Azure & Databricks, I’d be happy to connect.


Phone
+44 7471 566316
+91 75075 18753

Best way to reach me: email or a short LinkedIn message with context about your stack and challenges.